Documentation For Prompts
Prompts are taking over codebases. How do we maintain them?
Andrej Karpathy talks about software 1.0, 2.0, and 3.0.
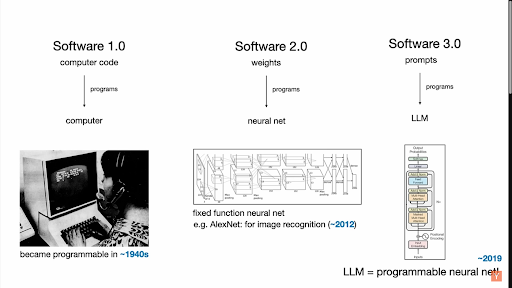
Karpathy's framework for software evolution.
He describes how 3.0, prompts, is taking over codebases.
We understand how to document software 1.0 (comments, docs) and 2.0 (docs, comments in your jupyter notebook), but 3.0 is tricky.
Can't you just write docs? You can, but engineers have been tricked not to because when you write the prompt, it looks like you are writing docs. You are not. A prompt blends a few technical choices together, making them difficult to untangle:
- Why did you settle on this prompt? What other prompts did you try?
- What is in the prompt because it is the rule (i.e. the definition of the task), and what did you add because it improved accuracy?
Without docs answering these questions, prompts become difficult to maintain. What if you need to switch to a faster, cheaper model: which parts of the prompt are safe for you to change without affecting the exact rules the prompt is meant to follow? What if you need to change the rules: which parts can you change without harming model accuracy?
Can't you just leave comments? You can leave them at the top of the prompt, but you can't leave them in your prompt.
You could break your prompt up into several variables and do some crazy string concatenation. This is what I recommend. I call it crazy because it kind of is, and nobody does it.
How do you make sure your concatenation formats everything correctly? This depends on the specifics of your codebase. Given that some concatenation is bound to happen in your prompts anyways (conditionals, all kinds of context engineering, the abstraction of your callLLM() helper function), building a way to view the exact LLM input for your prompt is productive.
Not a fan of this? Here are some alternatives.
You can try to use a kind of prompt versioning/sticky note-ing extension. Not everybody uses VSCode, so you have to make it work across editors. Having this extension always running in the background looking for line changes is a bit messy, too.
You can try to rely solely on evals for documenting your prompts. Prompts perform a task, so you almost always have a way to test them. You can annotate some of the examples, explaining what the model misses in item A and why detail B matters when you're looking at rule C. You should do this, too, but it can be a messy process:
- You write a prompt for a task, you ship it, you're done.
- A few weeks pass.
- An engineer goes to work on your prompt, upgrading it to a new model. They see that your best accuracy is 94.5% precision, 89.5% recall on the linked eval set.
- When they run the new model, they see 93.5% precision, 91% recall. This is an F1 score improvement: their work is done! Git push.
- Precision drops 10 percentage points in production. The new engineer reverts their change and investigates.
- Examining the diff between model runs, they realize that the false positive they introduced is one of the most prevalent types of content in production, whereas the improved recall came from rare cases, hurting production accuracy overall.
- They make a prompt change fixing the issue and examine the diff again until they are ready to push to production, repeating the above steps as needed.
Annotating your eval example with, "hey, this example is really common in production, make sure to get it right" would be nice. So would having two eval sets, one that covers a breadth of cases and another that matches the data distribution in production. And while you should strive to do both, neither is 100% feasible. If you got that prevalent example right the first time, you wouldn't even think to leave a comment on it.
If you had two eval sets, you would have to invest double the time into maintaining them—exactly like you would with a prompt. Not always feasible with time constraints.
What matters most is having a system that prevents you from repeating these mistakes. When the new engineer realizes what went wrong, they shouldn't fix it and forget it, they should leave documentation behind for the next person.
Whether you use documentation, comments, or both, this should live somewhere easily accessible and well-maintained.
What does a good, well-maintained prompt look like? Embarrassingly enough, all of my prompts are confidential. If anyone would like to submit an example, I will look it over and share a good one here :)